晓|SIGIR2025:MSL给大语言模型装上推荐目标导航仪!
旺晓通:深入浅出解读,轻松通晓技术
在如今这个信息爆炸的时代,推荐系统就像我们生活中的智能小助手。无论是在刷购物网站挑选心仪的商品,还是打开音乐APP寻找动听的旋律,又或是在视频平台上发现有趣的视频,推荐系统都在背后默默地发挥着作用,猜透我们的心思,给我们推送那些可能感兴趣的内容。
我们详细翻译解读最新技术,文末有相关信息。

作者:张长旺,图源:旺知识
而大语言模型(LLMs),凭借着强大的理解能力和丰富的知识储备,逐渐成为了推荐系统领域的“新宠”。研究人员都希望借助大语言模型的力量,让推荐系统变得更加智能、精准。但理想很丰满,现实却有点骨感。在将大语言模型应用到推荐系统的过程中,研究人员遇到了不少难题。这时候,一篇SIGIR2025 (CCF-A) 信息检索国际会议录用的论文《MSL:Not All Tokens Are What You Need for Tuning LLM as a Recommender》横空出世,提出了一种全新的方法,为解决这些难题带来了新的希望。接下来,就让我们一起走进这篇论文,看看它到底有什么神奇之处。

一、大语言模型进军推荐系统,状况百出
大语言模型这几年可太火了!它就像一个无所不知的“超级大脑”,能理解各种复杂的内容,还掌握着海量的知识。把它应用到推荐系统里,听起来简直是强强联合。想象一下,推荐系统有了大语言模型的加持,就像给购物助手配备了一个知识渊博的顾问,肯定能给我们推荐更合心意的东西。
于是,研究人员就开始行动啦。他们把大语言模型直接当作推荐器,把用户之前的互动记录整理成语言提示,就好比是给大语言模型“打小抄”,让它根据这些提示来猜测用户接下来可能喜欢的东西。这个方法听起来挺靠谱,在少样本学习、模型泛化和可解释性方面都取得了不错的成果,推荐性能也有了一定的提升。
但是,大语言模型原本可不是为推荐系统而生的,就像让一个短跑运动员去参加马拉松,多少有点“水土不服”。所以,为了让大语言模型更好地适应推荐系统的工作,研究人员会对它进行监督微调。这就好比是给运动员进行专项训练,让它能在特定的领域发挥出更好的水平。
在微调的时候,大家常用一种叫做语言建模损失(LML)的方法。这个LML原本是设计用来做语言生成任务的,就像是让大语言模型学习怎么写文章,生成通顺、合理的句子。在推荐系统里,它的任务就是增加代表正样本物品(也就是用户可能喜欢的物品)的概率,同时降低其他生成内容的概率。
听起来挺合理的,可实际操作起来却问题不断。
第一个问题是,LML的目标和推荐系统的目标严重不一致。推荐系统的目标是给用户推荐他们真正喜欢的东西,把正样本物品排在所有物品的前面,就像在超市里把顾客可能喜欢的商品放在显眼的位置。而研究人员通过理论和实验验证发现LML会浪费大量精力教会模型区分合法和非法物品,即倾向于使大模型输出的推荐物品是系统当中所存在的物品,不仅如此,对于该目标的优化会很大程度上阻碍对于推荐目标的优化,导致模型的推荐性能有限。
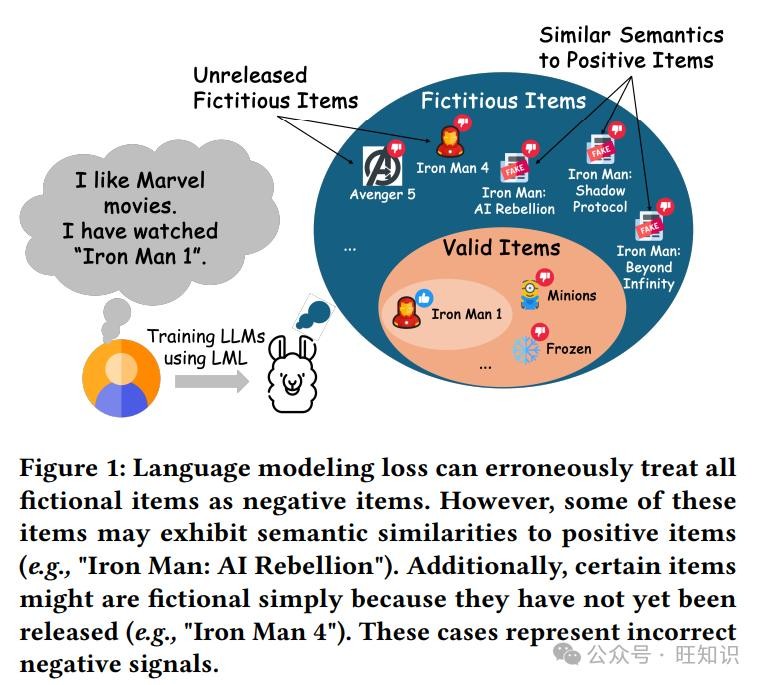
另一个问题是,LML会把所有虚构的物品描述都当成负样本,这就有点“一刀切”了。有些虚构的物品可能和正样本物品很相似,用户说不定会喜欢呢。比如说,有个漫威电影迷,他看过《钢铁侠1》,那像《钢铁侠:AI叛乱》这种虚构的电影,虽然还没上映,但从名字就能看出来和钢铁侠系列有关,他很可能会感兴趣。可LML却不管这些,直接把它当成用户不喜欢的东西,这就给大语言模型传递了错误的信号,让它很难准确地把握用户的喜好。
还有一种叫S-DPO的方法,它也想利用直接偏好优化来提升基于大语言模型的推荐效果。但它也有不少毛病,性能不太好,结果不稳定,计算成本还很高。就像是一辆车,开得不快,还老是出故障,油耗还特别高,肯定让人很头疼。
二、MSL闪亮登场,解决难题有妙招
面对LML的这些问题,研究人员提出了一个全新的解决方案——掩码Softmax损失(MSL)。这就像是给大语言模型在推荐系统里量身定制的一套“战斗服”,专门用来解决之前遇到的难题。
MSL的核心思路很简单,就是把那些可能导致虚构物品描述的无效标记给“屏蔽”掉。在计算损失的时候,不让这些无效标记参与进来,这样就能避免错误的负样本信号干扰大语言模型的判断。这就好比在超市里整理商品的时候,把那些不存在的商品模型都收起来,只留下真实的商品,这样顾客就能更清楚地看到自己想要的东西了。
MSL还有很多厉害的地方。
它和推荐系统的目标非常契合。通过理论分析发现,优化MSL等价于是在优化一个更贴近推荐系统NDCG指标的上界(这个指标可以衡量推荐系统的排名准确性,数值越高,推荐效果越好)。相比LML更能有效地优化推荐性能。这就好比给推荐系统找到了一条更准确的导航路线,让它能更快、更准地把用户喜欢的物品推荐出来。
而且,MSL实现起来也很容易。它的主要操作就是识别出有效的标记,这一步可以通过一种叫trie树(也叫前缀树)的结构来轻松完成。利用现有的工具包,只需要几行代码就能构建好trie树,然后就能计算出掩码矩阵,把LML改成MSL。这就好比给推荐系统升级了一个插件,只需要简单操作一下,就能让它的性能得到提升。
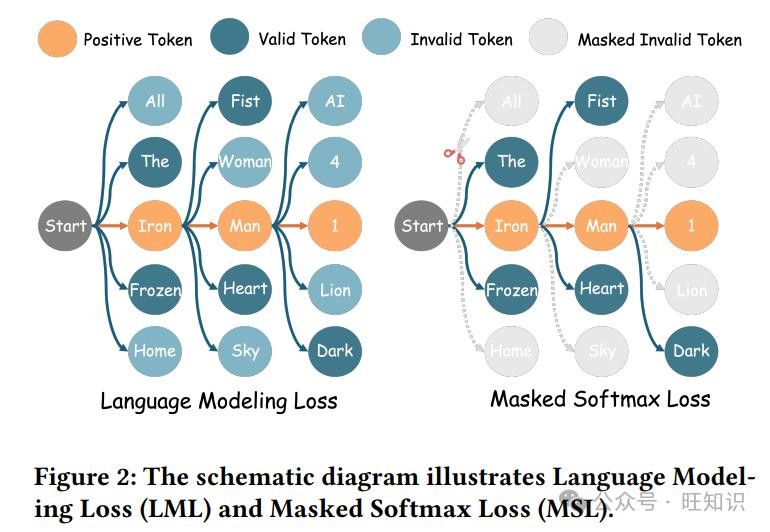
从效率方面来看,MSL也表现得相当出色。虽然构建trie树和掩码矩阵需要一些计算资源,但这个过程非常高效,在处理所有数据集的时候,都能在一秒内完成。而且,MSL在计算损失的时候,只考虑有效的标记,排除了大量无效标记,大大减少了计算量。这就好比在整理文件的时候,只保留有用的信息,扔掉那些没用的垃圾文件,让电脑运行得更快。
三、应对梯度消失,ATS来帮忙
MSL虽然理论上很完美,但在实际应用中还是遇到了一个小麻烦——梯度消失问题。这就好比一个人在跑步的时候,力气越来越小,最后跑不动了。
为什么会出现梯度消失呢?简单来说,MSL在计算概率的时候,分母里的有效标记数量变少了,这就导致某些概率值变得很大,而梯度的大小又和这些概率值有关。当概率值太大的时候,梯度就会变得很小,甚至接近于零,这样大语言模型在训练的时候就很难更新参数,影响了模型的学习效果。
为了解决这个问题,研究人员想到了一个办法——引入温度系数。这就好比给跑步的人喝点能量饮料,让他重新恢复力气。通过调整温度系数,可以改变概率的分布,让梯度的大小变得更合适,从而提高模型的性能。
但是,新的问题又来了。不同的数据集,最优的温度系数是不一样的。就好比不同的人适合不同的能量饮料配方,适合这个数据集的温度系数,换到另一个数据集上可能就不管用了。如果每次都要手动去调整这个超参数,那可太麻烦了,就像每次都要给不同的人调配不同的能量饮料,费时又费力。
这时候,自适应温度策略(ATS)就登场了。它就像是一个智能的能量饮料调配师,能够根据数据集的特点和模型的当前状态,自动调整温度系数,让概率值保持在一个合适的范围内,避免梯度消失。ATS是怎么做到的呢?它是根据有效标记的平均数量和模型预测的logits值(可以理解为模型对每个标记的“信心”程度)来计算出一个合适的温度系数。这样一来,就不用再手动去调整超参数了,大大提高了模型训练的效率和稳定性。
四、实验见真章,MSL实力超群
为了验证MSL的效果,研究人员进行了一系列实验。
在实验中,研究人员选用了四个真实世界的数据集,这些数据集在基于大语言模型的推荐研究中经常被用到,就像是厨师们常用的经典食材。他们把MSL和很多其他推荐方法进行了对比,这些方法包括传统的推荐器、大语言模型增强的推荐器、基于大语言模型的推荐器,还有同样改进了损失函数的S-DPO。
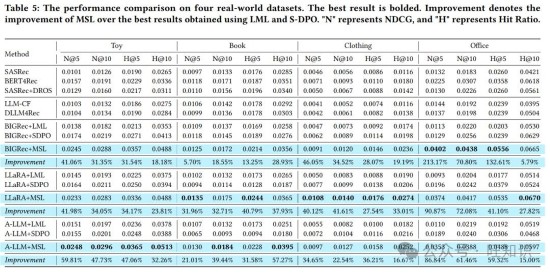
实验结果令人惊喜,MSL在各个数据集上都表现得非常出色,远远超过了其他的基线方法。在NDCG@10这个指标上,MSL平均提升了42.24%,就像是一个学生原本考试只能考60分,现在一下子提高到了85分以上,进步非常明显。
相比之下,其他方法就没有这么亮眼的表现了。像LLM-CF这种大语言模型增强的推荐器,在四个数据集中有三个都表现不佳,甚至出现了负增长。这就好比一个人本来想通过锻炼变得更强壮,结果却适得其反,变得更虚弱了。
S-DPO虽然也想改进推荐效果,但它的表现很不稳定,在一些数据集上不仅没有提升,反而出现了下降的情况。就像一辆车,有时候开得还不错,有时候却突然抛锚了。
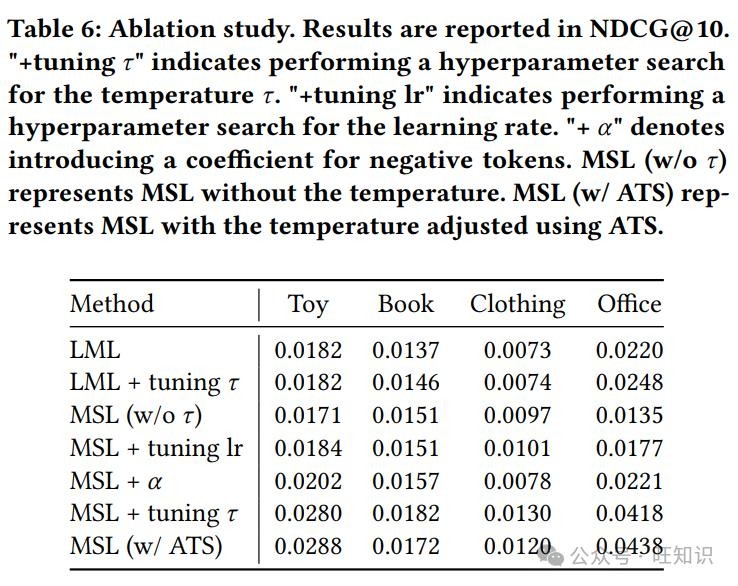
研究人员还对MSL进行了消融实验,就像把一辆车拆开来,看看每个零件都有什么作用。他们发现,温度系数对MSL的性能影响很大,如果没有温度系数的调整,MSL在某些数据集上甚至会比LML表现得更差。而ATS模块就像是一个智能的汽车导航系统,它的效果比手动调整超参数还要好,能够让MSL更稳定地发挥性能。
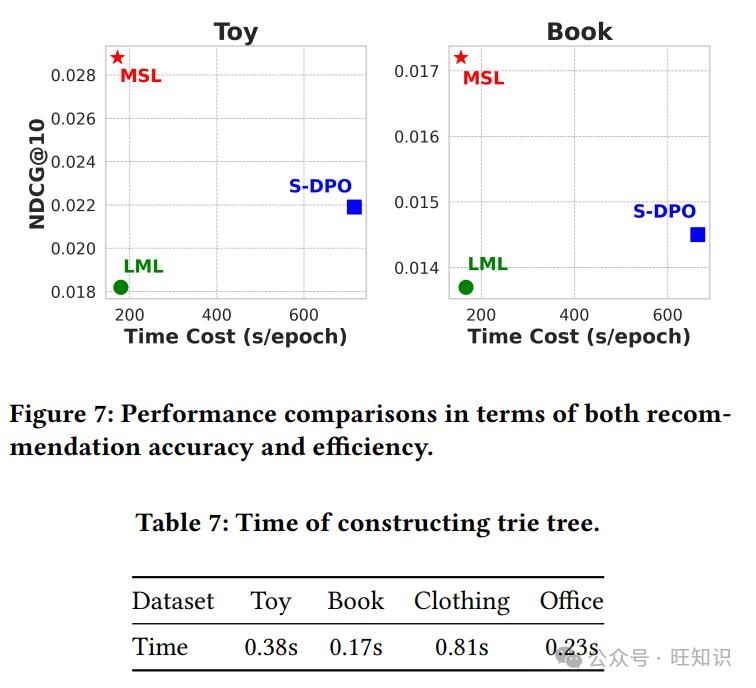
在效率方面,MSL也展现出了巨大的优势。和S-DPO相比,MSL在计算效率上有了大幅提升,在Toy和Book数据集上分别提高了315%和324%。这就好比一辆车原本开得很慢,现在换上了更强大的发动机,速度一下子快了好几倍。和LML相比,MSL也有一定的效率提升。这说明MSL不仅推荐效果好,而且运行起来还更“节省资源”,就像一辆既跑得快又省油的汽车。
五、MSL未来之路可期
MSL的出现,为基于大语言模型的推荐系统带来了新的突破。它通过改进损失函数,有效地解决了大语言模型在推荐系统应用中遇到的问题,让推荐系统的性能得到了显著提升。就像给推荐系统注入了一针“强心剂”,让它变得更加强大、智能。
这篇论文的研究成果不仅在理论上有重要意义,在实际应用中也有很大的价值。它为推荐系统的发展提供了新的思路和方法,让我们离更加精准、个性化的推荐服务又近了一步。
不过,研究人员并没有满足于此。他们认为,未来还有很多可以探索的方向。比如说,可以设计专门针对推荐系统的大语言模型架构,就像为推荐系统打造一辆独一无二的超级跑车,让它能更好地适应推荐任务的需求。这样一来,推荐系统的性能说不定还能有更大的提升空间。
相信在未来,随着技术的不断进步和研究的深入,推荐系统会变得越来越智能,给我们的生活带来更多的便利和惊喜。就像我们期待一辆辆更先进的汽车出现一样,我们也期待着更强大的推荐系统能够早日走进我们的生活,让我们在信息的海洋里畅游得更加轻松、愉快。

作者:张长旺,图源:旺知识
参考资料
• 标题:MSL: Not All Tokens Are What You Need for Tuning LLM as a Recommender• 作者:Bohao Wang、Feng Liu、Jiawei Chen、Xingyu Lou、Changwang Zhang、Jun Wang、Yuegang Sun、Yan Feng、Chun Chen、Can Wang• 单位:浙江大学、OPPO研究院、实在智能• 标签:推荐系统、大语言模型、损失函数、序列推荐• 概述: 文章提出一种适用于微调大语言模型(LLM)的掩码Softmax损失函数(MSL),用于解决传统语言建模损失(LML)在推荐系统应用中的局限性,同时提出自适应温度策略(ATS)解决MSL梯度消失问题,实验表明MSL能显著提升推荐性能。• 链接:ccccccc/3dwfn2bmqel.pdf
